Don't like this style? Click here to change it! blue.css
LOGIN:
Welcome .... Click here to logout
Daily Reminder: Mom's Spaghetti
Our compass through all of this is the desire for the following comfort food:
CONQUER ADDRESS RANDOMIZATION by a USE-AFTER-FREE vulnerability to leak a glibc address
WRITE-WHAT-WHERE using TCACHE-POISONING for arbitrary writing to glibc
CONTROL INSTRUCTION POINTER by overwriting the **FREE_HOOK** in glibc with system where "/bin/sh" is written in the free'd chunk
Tale of the 5 Bins
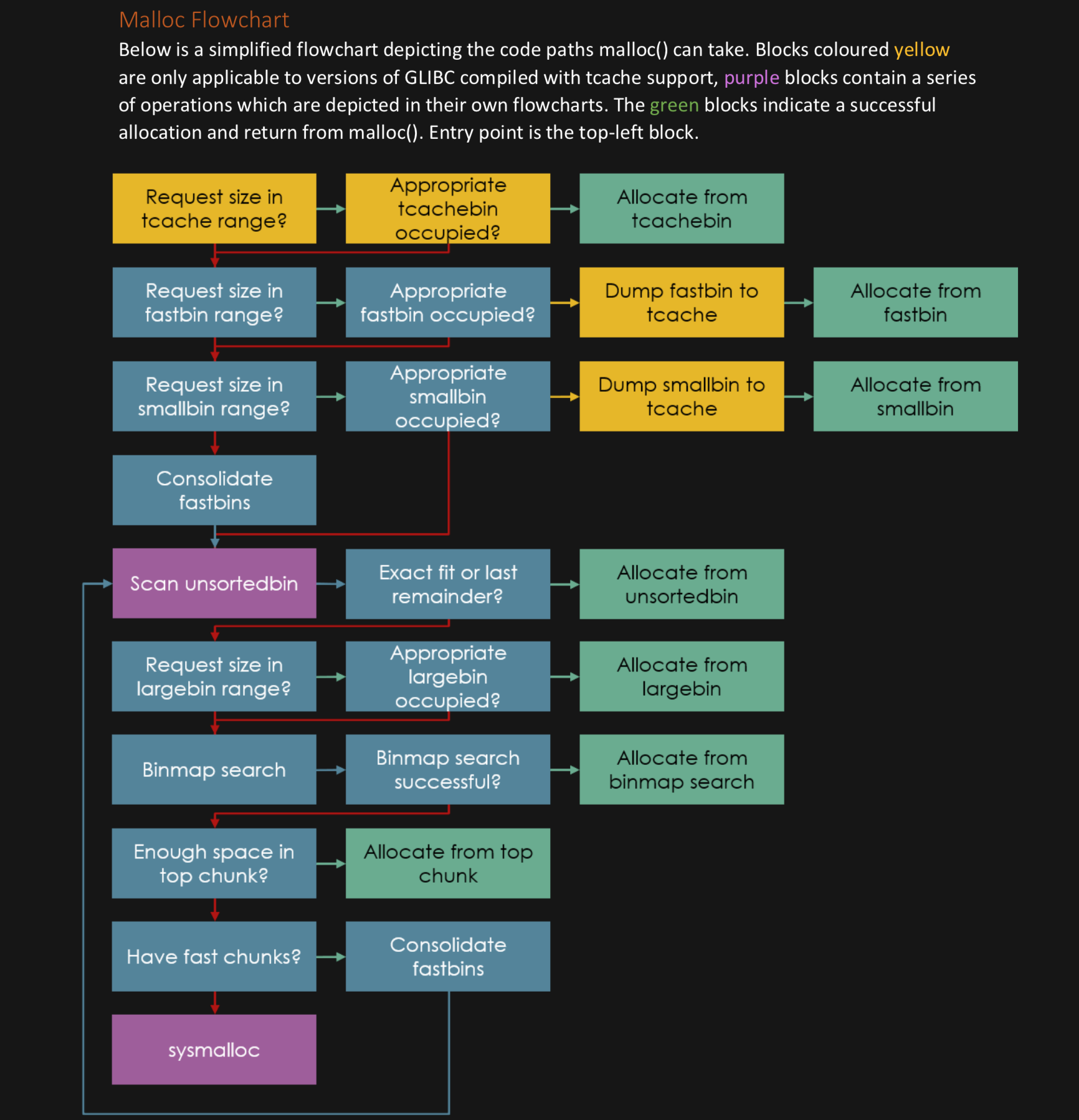
OK the goal of this is to understand WHY there are 5 different ways that glibc recycles chunks.
Each "bin" is a linked list for free'd (recycled) chunks.
There are 5 bins that can get used and the
goal of these notes are that you can reason about how to get a chunk into any particular bin.
The 5 bins are:
tcache binS
fastbinS
unsorted bin
small binS
large binS
The Bins: what, why, how
The word bin is really a linked-list holding re-usable (free'd) chunks
OK there are 5 types of bins. The first 3 are the "old-school" bins that are the basic fundamental approach to the heap:
62 small bins (doubly linked, one chunk-size per bin)
63 large bins (doubly linked AND a skip-list, a unique range of sizes per bin, chunks always sorted)
1 unsorted bin (doubly linked, all sizes, a temporary staging cache of recently free'd chunks waiting to be sorted into small/large bins)
The other 2 types are the "new-school" bin types:
10 fastbins (singly-linked chunks that are in-practice not going to be fully free'd, each chunk in a bin is the same size (0x20-0xb0))
64 tcache bins (max of 7 chunks per bin) THREAD-SAFE so not in glibc (which is shared over all threads) one bin per size from 0x20 to 0x410
The Why of it all
So put yourself in the shoes of a developer making code that runs the world.
Every server, every database, every operating system in the world is going to run on your malloc implementation.
You hear, all day, every day, from people complaining about your performance or your security issues.
So... you profile like crazy. You try to understand, statistically, how people are really using you. What the ratio of mallocs/frees are,
what the clustering patterns are, which sizes are requested most often, and in what order.
Every clock cycle matters.
Further, if you're servicing a server (you are) then each new socket or incoming connection will be a parallel thread of your socket process.
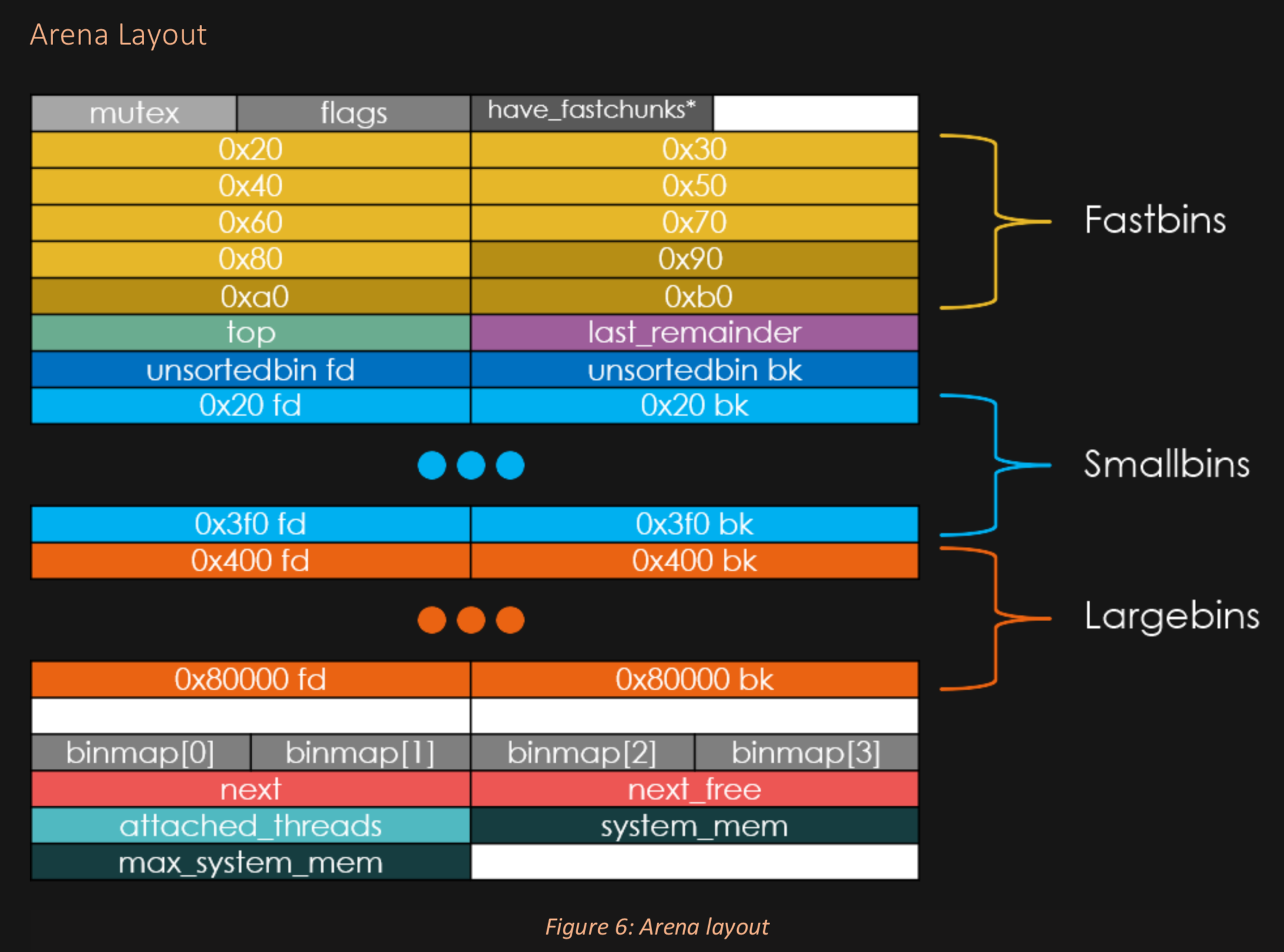
That means that the threads will actually SHARE the segments for your opcodes, glibc, and .data/.bss segments. Importantly your HEAP (and main_arena) ARE SHARED ACROSS THREADS.
Not the stack or registers though.
OK the baseline story: smallbins
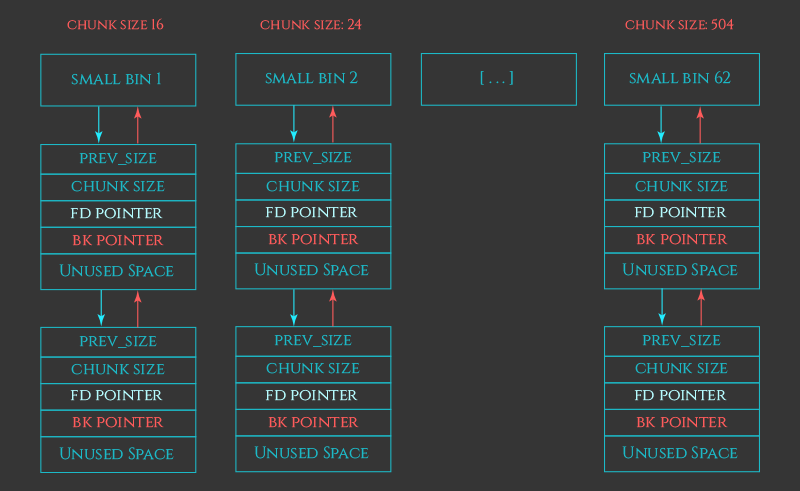
Small bins are doubly linked, one size per small bin in the range 0x20 to 0x3f0.
Let's pretend that the smallbins are populated with ready to malloc free'd chunks all lined up.
Then when it's time to malloc and we've decided to use a smallbin we find the linked-list / bin for that size and unlink
the VICTIM CHUNK (the name for the one about to be malloc'd) follow its bk pointer and replace that with its fd_pointer, follow its fd_pointer and replace that with its bk pointer.
Then once it is unlinked we return the VICTIM address.
Here are a ton of pictures:
You'll note that there are 62 smallbins and they use 124 addresses in an arena. (A forward and backward pointer each.)
Another note: smallbins are FIFO not LIFO. frees are added to the head and mallocs are taken from the tail
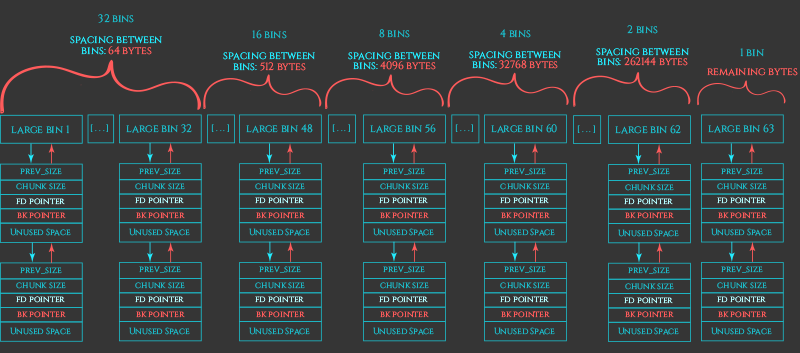
Largebins: similar but different
Largebins are also doubly-linked, but now, for the sake of space in the arenas we have a range of sizes per bin.
Each bin has a unique range which does not intersect with any other smallbin or largebin
Because each bin has more than once size we have to do some sorting in order to speed things up.
The ranges in each bin get wider the larger the sizes are:
This section is the slowest to use and the other optimizations are essentially to not need to do this.
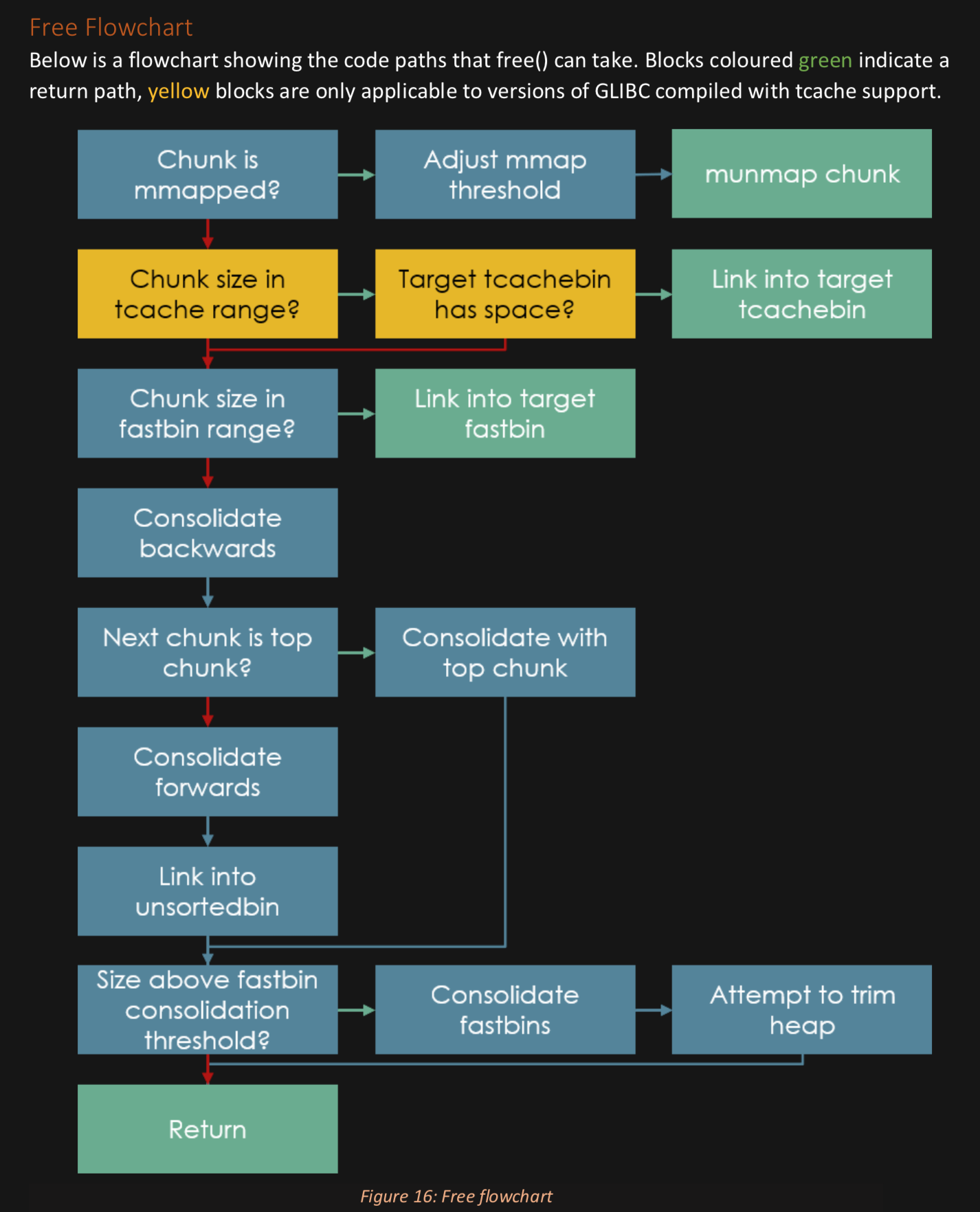
A normal free
When you free a chunk and fastbins/tcache are not involved then the process is roughly this:
If you were mmaped into existence then munmap out of existence (this is for GIANT chunks)
If your neighbors are also free perhaps you can consolidate with them
If you are next to the top chunk you can consolidate with the top chunk
Then mark your chunk as free and put it in a bin (the unsorted bin)
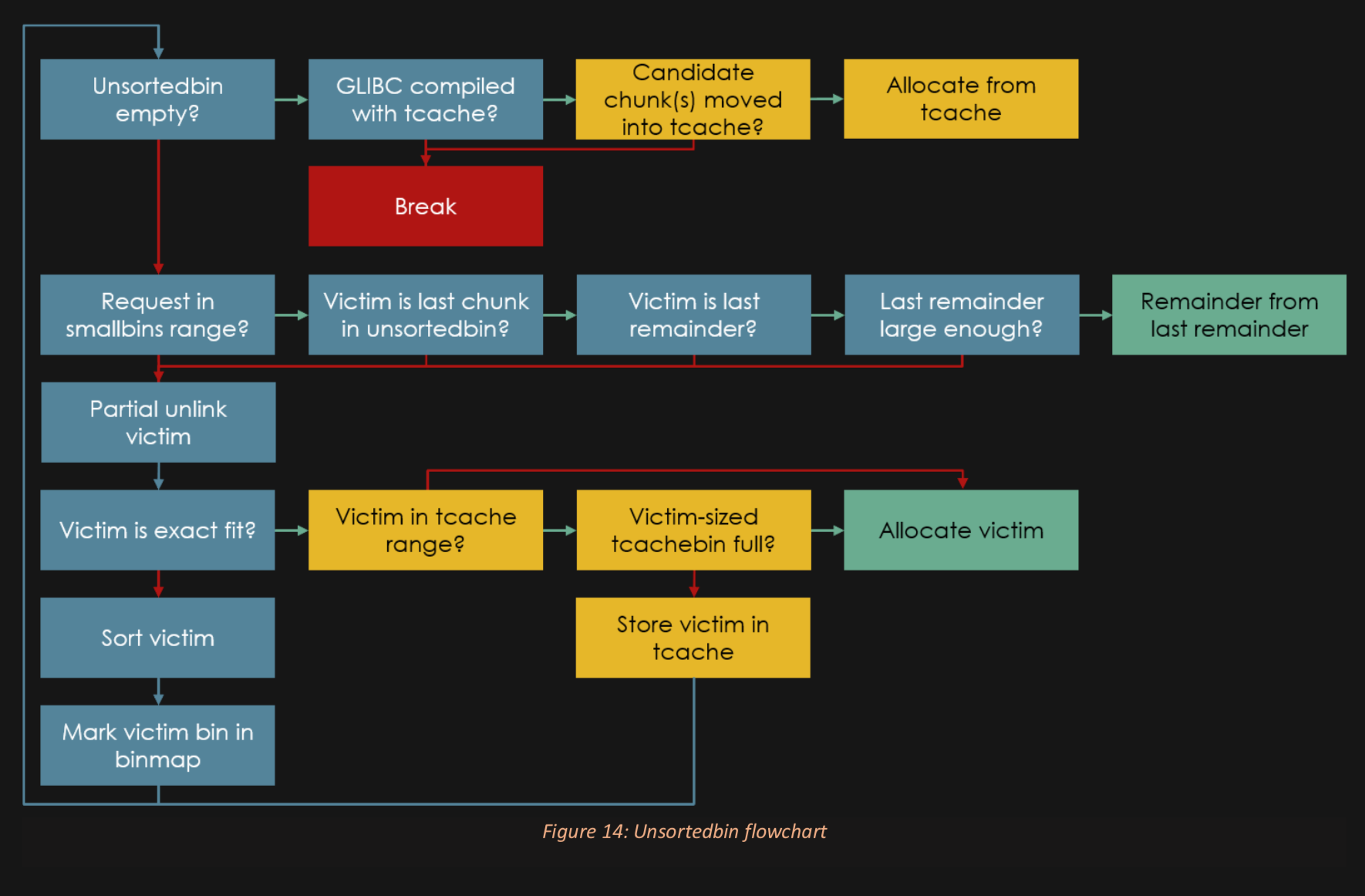
Unsorted bins: the quick cache
Since frees tend to come in clusters (I am done with this entire ARRAY of stuff), it's best not to start doing weird sorting and merging things too quickly.
Once we go through the unsorted bin we will move what we find into either the smallbins or largebins
tcache bins: first priority
The story:
tcache (thread safe cache) is a struct stored on the heap.
(One struct per thread)
It has the space for one address of each size from 0x20, 0x30, up to 0x410.
It also has space for one short number to count how many chunks are in each linked list.
The linked list is "singularly linked", i.e. only points forward never backward.
The addresses in tcache bins that are leakable are only ever HEAP addresses.
Here's what that struct looks like:
Here is WHY:
All other bins are controlled by glibc
These "thread" based bins allow independent threads to recycle/reuse their own chunks without locking glibc
They do NOTHING to attempt to consolidate or manage defragmentation
They don't even update the "prev chunk in use" flags
It's all about speed
In order to avoid eating all your RAM they limit each bin/linked-list to maximum 7 chunks
Extra Note:
After glibc 2.32 they started to "encrypt" the addresses in each chunk with a simple XOR